

Django之DRF

DRF(Django REST framework) 给Django提供了用于构建Web API 的强大而灵活的工具包,包括序列化器、认证、权限、分页、过滤和限流
本文学习自:大江狗
前置知识
DRF安装
官方文档:https://www.django-rest-framework.org/
pip安装:pip install djangorestframework
图形化操作:注册到项目的INSTALL_APPS中
1 | INSTALLED_APPS = [ |
序列化基础知识
每种编程语言都有各自的数据类型, 将属于自己语言的数据类型或对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化(seralization);反之则称为反序列化。
Python数据序列化
Python自带json模块的dumps方法可以将python常用数据格式(比如列表或字典)转化为json格式
1 | import json |
Django查询集序列化
Django专属的数据类型比如查询集QuerySet和ValueQuerySet类型数据,提供了自带的serializers类
1 | # Django Queryset to Json |
当使用values查询部分字段以提升些性能时,返回来的结果需要先转换成列表格式,再用 json.dumps()方法序列化成json格式
1 | import json |
与Django自带的serializers类相比,DRF的序列化器更强大,可以根据模型生成序列化器,还能对客户端发送过来的数据进行验证
符合RESTful规范的API
REST是REpresentational State Transfer三个单词的缩写,由Roy Fielding于2000年论文中提出。简单来说,就是用URI表示资源,用HTTP方法(GET, POST, PUT, DELETE)表征对这些资源进行增删查改的操作。
协议、域名、版本
尽量使用https协议,使用专属域名来提供API服务。API版本可以放在URL里面,也可以用HTTP的header进行内容协商
1 | https://api.example.com/v1 |
URI(统一资源标识符)
在RESTful架构中,每个网址代表一种资源,这个网络地址就是URI(URL是URI的一种)。因为URI对应一种资源,所以里面不能有动词,只能有名词。一般来说,数据库中的表都是同种记录的集合,所以API中的名词也应该使用复数形式。
1 | https://api.example.com/v1/users # 用户列表资源地址 |
一个 URI就应该是一个资源,本身不能包含任何动作
1 | # 传统的Django开发可能将URL写成如下 |
有时候URL比较长,可能由多个单词组成,建议使用中划线”-“分割,而不是下划线”_“作为分隔符;另外每个URL的结尾不能加斜线”/”。
1 | https://api.example.com/v1/user-management/users/{id} # ✅ |
HTTP请求方法
常用的五个HTTP请求方法(括号里是对应的SQL命令)
1 | GET(SELECT):从服务器取出资源(一项或多项)。 |
还有两个不常用方法HEAD和OPTIONS。HEAD和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息;OPTIONS极少使用,它主要用于获取当前URL所支持的方法。
过滤(filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。符合RESTful规范的API应该支持过滤。下面是一些常见的通过参数过滤的方式。
1 | ?limit=10:指定返回记录的数量 |
DRF与django-filter联用可以轻松实现过滤。
状态码(Status Codes)
服务器在处理客户端请求后还应向用户返回响应的状态码和提示信息,常见的有以下一些状态码。
1 | 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent) |
Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
1 | {"link": { |
示例引入序列化器与函数视图(FBV)
这部分将以博客为例,使用DRF提供的序列化器开发两个API接口并测试,下面是简要的api描述
1 | # 接口描述:文章列表资源。GET请求获取文章列表资源, POST请求提交新文章 |
准备工作
搭建项目
1 | # 创建虚拟环境 |
下面是在settings.py中注册app
1 | INSTALLED_APPS =( |
创建模型
在blog/models.py中创建文章模型与用户模型
1 | from django.db import models |
其中gettext_lazy是用于字符串延迟翻译,get_user_model是Django自带的用户模型
之后执行如下命令同步数据库并创建超级用户
1 | python manage.py makemigrations |
接下来我们就可以使用Django自带的后台添加文章与用户,方便后续api测试
配置Django后台
编辑blog/admin.py文件
1 | from django.contrib import admin |
运行python manage.py runserver,即可通过admin路由进入Django自带的后台管理平台
自定义序列化器
序列化器可将复杂的数据类型(如 Django 模型实例)转换为可传输的格式(如 JSON),也可以将接收到的数据反向转换为模型实例,同时自动进行数据验证和处理
DRF提供了Serializer类和ModelSerializer类两种方式供你自定义序列化器。前者需手动指定需要序列化和反序列化的字段,后者根据模型(model)生成需要序列化和反序列化的字段,可以使代码更简洁
使用Serializer类
在blog目录下创建一个名为serializers.py的文件,并添加
1 | from rest_framework import serializers |
序列化器类的第一部分定义了序列化/反序列化的字段。create()和update()方法定义了在调用serializer.save()时如何创建和修改完整的实例
序列化器类与Django Form类非常相似,并在各种字段中设置各种验证,例如required,max_length和default
定义序列化器时一定要注明哪些是仅可读字段(read-only fields),哪些是普通字段。对于read-only fields,客户端是不需要也不能够通过POST或PUT请求提交相关数据进行反序列化的
本例中和create_date都是由模型自动生成,每个article的author我们也希望在视图中与request.user绑定,而不是由用户通过POST或PUT自行修改,所以这些字段都是read-only。相反title,body和status是用户可以添加或修改的字段,所以未设成read-only
使用ModelSerializer类
ArticleSerializer类中重复了很多包含在Article模型(model)中的字段信息。使用ModelSerializer类可以重构序列化器类,使整体代码更简洁
1 | class ArticleSerializer(serializers.ModelSerializer): |
编写API视图
接下来我们将编写两个基于函数的视图:article_list和article_detail,后续会介绍基于类的视图
编辑blog/views.py文件,添加以下内容
1 | from rest_framework import status |
这两个函数视图看似和Django普通函数视图非常类似,但其作用大不相同。这里我们使用了DRF提供的@api_view这个非常重要的装饰器,实现了以下几大功能:
- 与Django传统函数视图相区分,强调这是API视图,并限定了可以接受的请求方法
- 拓展了Django原来的request对象。新的request对象不仅仅支持request.POST提交的数据,还支持其它请求方式如PUT或PATCH等方式提交的数据,所有的数据都在
request.data字典里。这对开发Web API非常有用
我们不再显式地将请求或响应绑定到特定的内容类型比如HttpResponse和JSONResponse,我们统一使用Response方法返回响应,该方法支持内容协商,可根据客户端请求的内容类型返回不同的响应数据。
20行与42行的context={'request': request}的作用是解决序列化器中CurrentUserDefault 的依赖
给URLs添加可选的格式后缀
为了充分利用我们的响应不再与单一内容类型连接,我们可以为API路径添加对格式后缀(.json或.api)的支持
我们之前的视图函数定义时已经加入 format=None,接下来更改blog/urls.py文件,给现有的urlpatterns加上format_suffix_patterns
1 | from django.urls import re_path |
最后把app的urls加入到项目URL配置apiproject/urls.py文件中
1 | from django.contrib import admin |
API测试
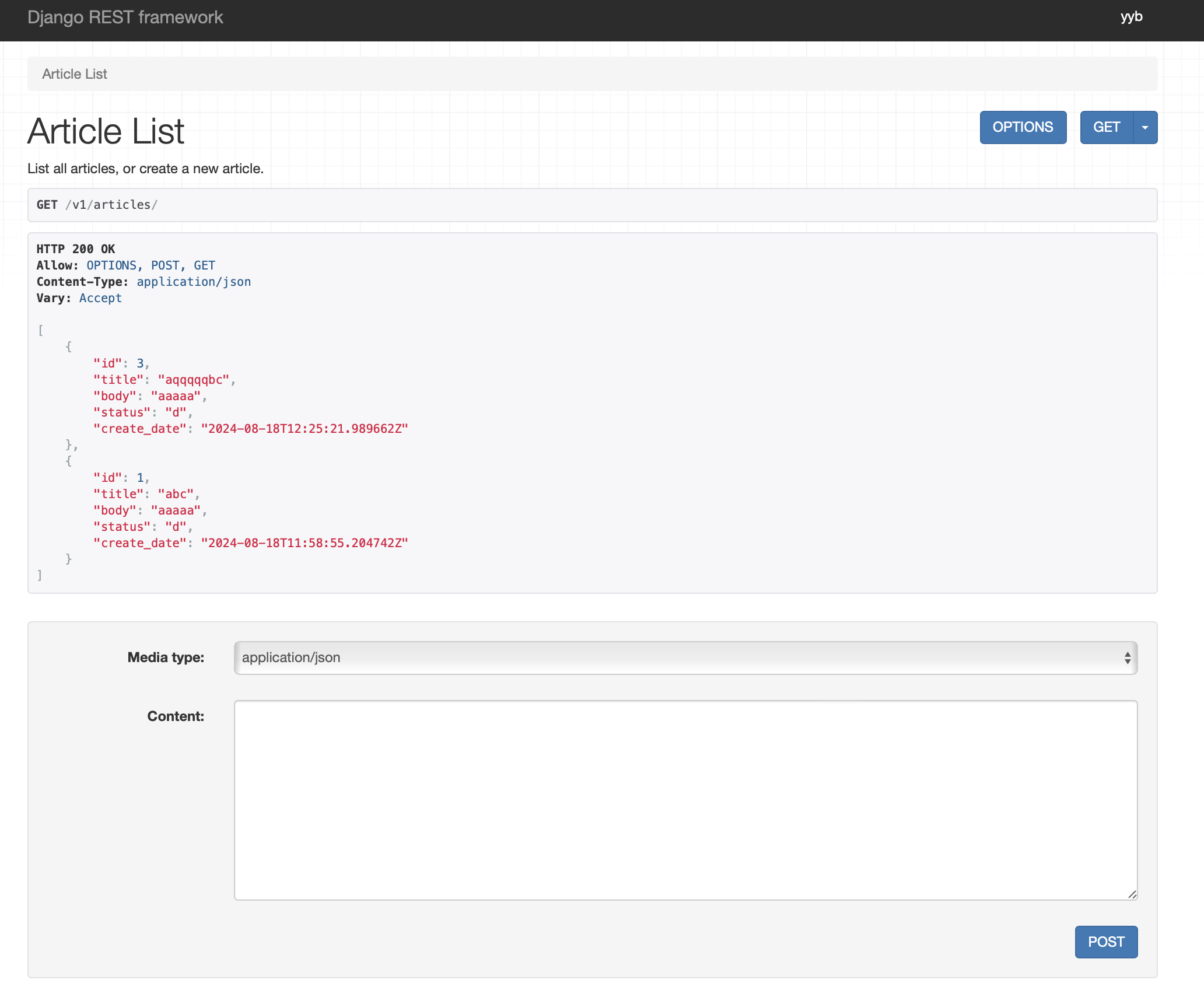
测试工具有很多,curl命令、postman、apifox(推荐),这里使用DRF自带的图形化测试界面
直接使用浏览器访问http://127.0.0.1:8000/v1/articles,即可看到图形化测试界面,可自行通过图形化交互做测试
基于类的视图和视图集
一个中大型的Web项目代码量通常是非常大的,如果全部使用函数视图写,那么代码的复用率是非常低的。而使用类视图呢,就可以有效的提高代码复用,因为类是可以被继承的,可以拓展的
DRF推荐使用基于类的视图(CBV)来开发API, 并提供了4种开发CBV开发模式:
- 使用基础的
APIView类 - 使用Mixins类和
GenericAPI类混配 - 使用通用视图
generics.*类, 比如generics.ListCreateAPIView - 使用视图集
ViewSet和ModelViewSet
使用基础APIView类
DRF的APIView类继承了Django自带的View类, 一样可以按请求方法调用不同的处理函数,比如get方法处理GET请求,post方法处理POST请求
不过DRF的APIView要强大得多。它不仅支持更多请求方法,而且对Django的request对象进行了封装,可以使用request.data获取用户通过POST, PUT和PATCH方法发过来的数据,而且支持插拔式地配置认证、权限和限流类(后面会介绍)
我们可以更新之前blog/views.py中的代码
1 | from rest_framework.views import APIView |
类视图需要调用as_view()的方法才能在视图中实现查找指定方法,接下来修改blog/urls.py中的代码
1 | from django.urls import re_path |
这中方法与之前基于函数的视图差别并不大,最大不同的是不需要在对用户的请求方法进行判断,该视图可以自动将不同请求转发到相应处理方法,逻辑上也更清晰
用Mixin类和GenericAPI类混配
使用基础的APIView类并没有大量简化代码,比如需要对文章类别Category模型也进行序列化和反序列化,我们只需要复制Article视图代码,将Article模型改成Category模型, 序列化类由ArticleSeralizer类改成CategorySerializer类就行了
对于这些通用的增删改查行为,DRF已经提供了相应的Mixin类。Mixin类可与generics.GenericAPI类联用,灵活组合成你所需要的视图
下面我们更改视图函数为:
1 | from rest_framework import mixins |
GenericAPIView 类继承了APIView类,提供了基础的API视图。它对用户请求进行了转发,并对Django自带的request对象进行了封装。不过它比APIView类更强大,因为它还可以通过queryset和serializer_class属性指定需要序列化与反序列化的模型或queryset及所用到的序列化器类
这里的 ListModelMixin 和 CreateModelMixin类则分别引入了.list() 和.create()方法,当用户发送get请求时调用Mixin提供的list()方法,将指定queryset序列化后输出,发送post请求时调用Mixin提供的create()方法,创建新的实例对象
DRF还提供RetrieveModelMixin, UpdateModelMixin和DestroyModelMixin类,实现了对单个对象实例的查、改和删操作
perform_create这个钩子函数是CreateModelMixin类自带的,用于执行创建对象时需要执行的其它方法,比如发送邮件等功能,有点类似于Django的信号。类似的钩子函数还有UpdateModelMixin提供的perform_update方法和DestroyModelMixin提供的perform_destroy方法
使用通用视图Generics.*类
将Mixin类和GenericAPI类混配,已经减少了一些代码,但还可以做得更好,比如将get请求与mixin提供的list方法进行绑定感觉有些多余。幸好DRF还提供了一套常用的将 Mixin 类与 GenericAPI类已经组合好了的视图,开箱即用,可以进一步简化我们的代码
1 | from .models import Article |
顾名思义,generics.ListCreateAPIView类支持List、Create两种视图功能,分别对应GET和POST请求。generics.RetrieveUpdateDestroyAPIView支持Retrieve、Update、Destroy操作,其对应方法分别是GET、PUT和DELETE
其它常用generics类视图还包括ListAPIView, RetrieveAPIView, RetrieveUpdateAPIView等等。你可以根据实际需求使用,为你的API写视图时只需要定义queryset和serializer_class即可
使用视图集ViewSet
使用通用视图generics类后视图代码已经大大简化,但是ArticleList和ArticleDetail两个类中queryset和serializer_class属性依然存在代码重复。使用视图集可以将两个类视图进一步合并,一次性提供List、Create、Retrieve、Update、Destroy这5种常见操作,这样queryset和seralizer_class属性也只需定义一次就好, 这就变成了视图集(viewset)
1 | from .models import Article |
使用视图集后,我们需要使用DRF提供的路由router来分发urls,因为一个视图集现在对应多个urls,而不像之前的一个url对应一个视图函数或一个视图类
1 | from django.urls import re_path |
一个视图集对应List、Create、Retrieve、Update、Destroy这5种操作。有时候我只需要其中的一种或几种操作,可在urls.py中指定方法映射即可
1 | from django.urls import re_path |
另外DRF还提供了ReadOnlyModelViewSet这个类,它仅支持list和retrive这两个可读的操作
1 | from rest_framework import viewsets |
Django视图集viewset代码最少,但这是以牺牲了代码的可读性为代价的,因为它对代码进行了高度地抽象化。另外urls由router生成,不如自己手动配置的清楚
总结
使用基础的
APIView类优点:灵活性最高,可以完全控制请求和响应的处理逻辑;适合处理复杂的、需要自定义处理逻辑的 API 端点。
缺点:需要手动编写大量样板代码,如处理请求方法、验证和序列化。
适合复杂的场景,但不推荐在常规的 CRUD 操作中使用,因为会导致代码冗余。
使用
Mixins类和GenericAPIView类混配优点:提供了比
APIView更高的代码复用性;保留了一定的灵活性,允许在需要的地方进行自定义。缺点:尽管比
APIView更简洁,但仍然需要手动组合不同的 mixin,代码相对较多;对于新手来说,理解 mixin 的组合和使用可能有些复杂。适合需要部分自定义逻辑的场景,但更推荐选择通用generics类
使用通用视图
generics.*类优点:提供了高度集成的常见视图(如
ListCreateAPIView),可以快速创建标准的 CRUD API;极大地减少了样板代码,使代码更加简洁易读。缺点:灵活性稍有下降,如果需要高度自定义逻辑,可能需要覆盖默认方法或引入额外的逻辑。
在大多数常见的 API 开发场景中,这是最推荐的方式,因为它在简洁性和功能性之间找到了很好的平衡。
使用视图集
ViewSet和ModelViewSet优点:提供了最高程度的代码复用和简洁性,尤其是
ModelViewSet,可以自动处理所有 CRUD 操作;与 DRF 的路由系统紧密集成,能自动生成标准的路由,非常适合快速开发 RESTful API。缺点:灵活性最低,如果需要特殊的逻辑处理,可能需要重写或覆盖许多方法。
在标准化的 CRUD 操作中,这是最推荐的方式,可以快速开发 API。但在需要高度定制的场景下,可能需要退回到使用
generics或mixin。
序列化器进阶
这一节关注如何修改序列化器,控制序列化后响应数据的输出格式;如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何动态加载或重写序列化器类自带的方法
改变序列化器的输出
指定source来源
打开blog/serializers.py,新建两个可读字段author、status字段,用以覆盖原来Article模型默认的字段,其中指定author字段的来源为单个author对象的username,status字段为get_status_display方法返回的完整状态
1 | class ArticleSerializer(serializers.ModelSerializer): |
这个看似完美,但里面其实有个问题。我们定义了一个仅可读的status字段把原来的status字段覆盖了,这样反序列化时用户将不能再对文章发表状态进行修改(原来的status字段是可读可修改的)
一个更好的方式在ArticleSerializer新增一个为full_status的可读字段,而不是简单覆盖原本可读可写的字段
使用SerializerMethodField方法
status都是以Published或Draft英文字符串表示的,如果想在输出的json格式数据中新增cn_status字段,但cn_status本身并不是Article模型中存在的字段,这时可以使用SerializerMethodField,它可用于将任何类型的数据添加到对象的序列化表示中, 非常有用
编辑blog/serializers.py
1 | class ArticleSerializer(serializers.ModelSerializer): |
需要注意的是SerializerMethodField通常用于显示模型中原本不存在的字段,类似可读字段,你不能通过反序列化对其直接进行修改
使用 to_representation方法
to_representation() 允许我们改变序列化的输出内容, 给其添加额外的数据
假设我们更改文章模型与序列化器:
1 | class Article(models.Model): |
现在如果我们希望输出数据添加一个total_likes点赞总数的字段,我们只需要在序列化器类里重写to_representation方法
1 | class ArticleSerializer(serializers.ModelSerializer): |
使用嵌套序列化器
目前我们文章中的author字段实际上对应的是一个User模型实例化后的对象,既不是一个整数id,也不是用户名这样一个简单字符串,我们可以使用嵌套序列化器显示更多用户对象信息
1 | class UserSerializer(serializers.ModelSerializer): |
其中我们还需要手动指定read_only=True这个选项。尽管我们在Meta选项已经指定了author为read_only_fields, 但使用嵌套序列化器时还需要重新指定一遍
设置关联模型深度
1 | class ArticleSerializer(serializers.ModelSerializer): |
这种方法虽然简便,但使用时要非常小心,因为它会展示关联模型中的所有字段。比如下例中连密码password都展示出来了,显然不是我们想要的
关系序列化
若现在反过来要对用户信息进行序列化,要求返回信息里包含用户信息及所发表的文章列表,但用户User模型没有article这个字段,这时应该使用Django REST Framework提供的关系序列化方法。
PrimaryKeyRelatedField
1 | class UserSerializer(serializers.ModelSerializer): |
StringRelatedField
如果希望文章列表不以id形式展现,而是直接体现文章title,可以使用StringRelatedField
1 | class UserSerializer(serializers.ModelSerializer): |
StringRelatedField会直接返回每篇文章对象通过__str__方法定义的字段
HyperlinkedRelatedField
有时我们希望更进一步,不仅仅提供每篇文章的id或title列表,而是直接提供每篇文章对应的url列表,这样访问每个url可以获得更多关于文章的信息。这时就可以使用HyperlinkedRelatedField,它需要接收一个view的别名(本例为article-detail)
1 | class UserSerializer(serializers.ModelSerializer): |
其中注意要同步修改blog/urls.py中的路由别名: re_path(r'^articles/(?P<pk>[0-9]+)$', views.ArticleDetail.as_view(), name='article-detail'),
数据验证(Validation)
在反序列化数据时,必需对用户提交的数据进行验证。在尝试访问经过验证的数据或保存对象实例之前,总是需要显示地调用 is_valid()方法。如果发生任何验证错误,.errors 属性将包含表示结果错误消息的字典,如下所示
1 | serializer = CommentSerializer(data={'email': 'foobar', 'content': 'baz'}) |
.is_valid() 方法使用可选的 raise_exception 标志,如果存在验证错误,将会抛出 serializers.ValidationError 异常
字段级别验证
我们可以通过向 Serializer 子类中添加 .validate_<field_name> 方法来指定自定义字段级的验证。这些类似于 Django 表单中的 .clean_<field_name> 方法。这些方法采用单个参数,即需要验证的字段值
1 | from rest_framework import serializers |
如果在序列化器上声明了 <field_name> 的参数为 required=False,那么如果不包含该字段,则此验证步骤不会发生
对象级别验证
要执行需要访问多个字段的任何其他验证,可添加名为 .validate() 的方法到 Serializer 子类中。此方法采用单个参数,该参数是字段值的字典。如果需要,它应该抛出 ValidationError 异常,或者只返回经过验证的值
1 | from rest_framework import serializers |
验证器
序列化器上的各个字段都可以包含验证器,通过在字段实例上声明
1 | def title_gt_90(value): |
DRF还提供了很多可重用的验证器,比如UniqueValidator,UniqueTogetherValidator等等。通过在内部 Meta 类上声明来包含这些验证器,如下所示。下例中会议房间号和日期的组合必须要是独一无二的
1 | class EventSerializer(serializers.Serializer): |
重写序列化器的create和update方法
假设我们有个Profile模型与User模型是一对一的关系,当用户注册时我们希望把用户提交的数据分别存入User和Profile模型,这时我们就不得不重写序列化器自带的create方法了。下例演示了如何通过一个序列化器创建两个模型对象
1 | class UserSerializer(serializers.ModelSerializer): |
同时更新两个关联模型实例时也同样需要重写update方法
1 | def update(self, instance, validated_data): |
因为序列化器使用嵌套后,创建和更新的行为可能不明确,并且可能需要相关模型之间的复杂依赖关系,REST framework要求你始终显式的编写这些方法。默认的 ModelSerializer .create() 和 .update()方法不包括对可写嵌套表示的支持,所以我们总是需要对create和update方法进行重写
动态加载序列化器
有时在类视图里不希望通过通过serializer_class指定固定的序列化器类,而是希望动态的加载序列化器,你可以重写get_serializer_class方法
1 | class UserViewSet(CreateModelMixin, |
认证与权限
目前的 API 对谁可以新增、编辑或删除文章资源(Article)没有限制,本节中希望通过基本的认证(Authentication)与权限(Permission)来实现一些更实用的功能:
- 只有经过身份验证的用户可以创建article文章(匿名用户不允许通过POST提交新文章)
- 未经身份验证的请求应具有完全只读访问权限
- 单篇article资源始终与创建者相关联,只有 article 的创建者可以更新或删除它
认证与权限的区别
认证(Authentication)与权限(Permission)不是一回事。认证是通过用户提供的用户ID/密码组合或者Token来验证用户的身份。权限(Permission)的校验发生验证用户身份以后,是由系统根据分配权限确定用户可以访问何种资源以及对这种资源进行何种操作,这个过程也被称为授权(Authorization)
无论是Django还是DRF, 当用户成功通过身份验证以后,系统会把已通过验证的用户对象与request请求绑定,这样一来你就可以使用request.user获取这个用户对象的所有信息了
给视图添加权限
在Django传统视图开发中你可能会使用@login_required和@permission_required这样的装饰器要求用户先登录或进行权限验证
在DRF中你不需要做,这是因为REST framework 包含许多默认权限类,我们可以用来限制谁可以访问给定的视图。在这种情况下,我们需要的是 IsAuthenticatedOrReadOnly 类,它将确保经过身份验证的请求获得读写访问权限,未经身份验证的请求将获得只读读的权限。
修改blog/views.py:
1 | from rest_framework import generics |
此时退出登录,再访问文章资源列表或单篇文章资源时,你会看到红色的delete按钮和添加修改表单都已消失,当重新登录验证身份后,你又可以看到delete按钮和修改表单了
DRF中你可以将登录页面api-auth添加到你的项目urls中,然后访问api-auth/login/就可以看到专门的DRF的登录页面
1 | from django.contrib import admin |
DRF自带权限类
除了IsAuthenticatedOrReadOnly 类,DRF自带的常用权限类还包括:
IsAuthenticated类:仅限已经通过身份验证的用户访问;AllowAny类:允许任何用户访问;IsAdminUser类:仅限管理员访问;DjangoModelPermissions类:只有在用户经过身份验证并分配了相关模型权限时,才会获得授权访问相关模型。DjangoModelPermissionsOrReadOnly类:与前者类似,但可以给匿名用户访问API的可读权限。DjangoObjectPermissions类:只有在用户经过身份验证并分配了相关对象权限时,才会获得授权访问相关对象。通常与django-gaurdian联用实现对象级别的权限控制。
自定义权限
大多数情况下,默认的权限类不能满足我们的要求,这时就需要自定义权限了。自定义的权限类需要继承BasePermission类并根据需求重写has_permission(self,request,view)和has_object_permission(self,request, view, obj)方法。你还可以通过message自定义返回的错误信息
之前IsAuthenticatedOrReadOnly 类并不能实现只有文章 article 的创建者才可以更新或删除它,这时我们还需要自定义一个名为IsOwnerOrReadOnly 的权限类,把它加入到ArticleDetail视图里
在blog文件夹下创建permissions.py,添加如下代码:
1 | from rest_framework import permissions |
然后修改我们的视图,IsOwnerOrReadOnly 的权限类,把它加入到ArticleDetail视图的permission_classes里
DRF支持权限类的插拔
更多设置权限方式
在前面的案例中,我们都是在基于类的API视图里通过permission_classes属性设置的权限类。如果你有些权限是全局或全站通用的,你还可以在settings.py中使用 DEFAULT_PERMISSION_CLASSES 全局设置默认权限策略。
1 | REST_FRAMEWORK = { |
如果未指定,则此设置默认为允许无限制访问
如果习惯使用基于函数的视图编写API,可以按如下方式给你的函数视图添加权限。
1 | from rest_framework.decorators import api_view, permission_classes |
当你通过类属性或装饰器设置新的权限类时,视图会覆盖 settings.py 中设置的默认权限。
认证详解与token认证
前一部分我们使用了Django默认的基于session的认证方式,实际前后端分离开发项目中后台更多采用的是token(令牌认证)
认证
身份验证是将传入的请求对象(request)与一组标识凭据(例如用户名+密码或者令牌token)相关联的机制。REST framework 提供了一些开箱即用的身份验证方案,并且还允许你实现自定义方案
DRF的每个认证方案实际上是一个类。你可以在视图中使用一个或多个认证方案类。REST framework 将尝试使用列表中的每个类进行身份验证,并使用成功完成验证的第一个类的返回的元组设置 request.user 和request.auth
用户通过认证后request.user返回Django的User实例,否则返回AnonymousUser的实例。request.auth通常为None。如果使用token认证,request.auth可以包含认证过的token
DRF自带认证方案
Django REST Framework提供了如下几种认证方案:
- Session认证
SessionAuthentication类:此认证方案使用Django的默认session后端进行身份验证。当客户端发送登录请求通过验证后,Django通过session将用户信息存储在服务器中保持用户的请求状态。Session身份验证适用于与你的网站在相同的Session环境中运行的AJAX客户端 (注:这也是Session认证的最大弊端) - 基本认证
BasicAuthentication类:此认证方案使用HTTP 基本认证,针对用户的用户名和密码进行认证。使用这种方式后浏览器会跳出登录框让用户输入用户名和密码认证。基本认证通常只适用于测试 - 远程认证
RemoteUserAuthentication类:此认证方案为用户名不存在的用户自动创建用户实例。这个很少用,具体见文档 - Token认证
TokenAuthentication类:该认证方案是DRF提供的使用简单的基于Token的HTTP认证方案。当客户端发送登录请求时,服务器便会生成一个Token并将此Token返回给客户端,作为客户端进行请求的一个标识。以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。后面我们会详细介绍如何使用这种认证方案
DRF中设置认证方案
设置默认的全局认证方案
1 | # settings.py |
在基于类的视图(CBV)中使用
1 | from rest_framework.authentication import SessionAuthentication, BasicAuthentication |
在基于函数的视图中使用
1 | from rest_framework.decorators import api_view, authentication_classes, permission_classes |
自定义认证方案
要实现自定义的认证方案,首先要继承BaseAuthentication类并且重写.authenticate(self, request)方法。如果认证成功,该方法应返回(user, auth)的二元元组,否则返回None
在某些情况下,你可能不想返回None,而是希望从.authenticate()方法抛出AuthenticationFailed异常。通常你应该采取的方法是:
- 如果不尝试验证,返回
None。还将检查任何其他正在使用的身份验证方案 - 如果尝试验证但失败,则抛出
AuthenticationFailed异常。无论任何权限检查也不检查任何其他身份验证方案,立即返回错误响应
你也可以重写.authenticate_header(self, request)方法。如果实现该方法,则应返回一个字符串,该字符串将用作HTTP 401 Unauthorized响应中的WWW-Authenticate头的值。如果.authenticate_header()方法未被重写,则认证方案将在未验证的请求被拒绝访问时返回HTTP 403 Forbidden响应。
以下示例将以自定义请求头中名称为’X_USERNAME’提供的用户名作为用户对任何传入请求进行身份验证,其它类似自定义认证需求比如支持用户同时按用户名或email进行验证。
1 | from django.contrib.auth.models import User |
前后端分离时为何推荐token认证
- Token无需存储降低服务器成本,session是将用户信息存储在服务器中的,当用户量增大时服务器的压力也会随着增大。
- 防御CSRF跨站伪造请求攻击,session是基于cookie进行用户识别的, cookie如果被截获,用户信息就容易泄露。
- 扩展性强,session需要存储无法共享,当搭建了多个服务器时其他服务器无法获取到session中的验证数据用户无法验证成功。Token可以实现服务器间共享,这样不管哪里都可以访问到。
- Token可以减轻服务器的压力,减少频繁的查询数据库。
- 支持跨域访问, 适用于移动平台应用
TokenAuthentication
DRF自带的TokenAuthentication方案可以实现基本的token认证,整个流程如下:
初始设置
修改settings.py, 加入如下app并设置认证方式
1 | INSTALLED_APPS = ( |
同时不要忘记做一次数据库迁移python manage.py migrate,生成token表
生成token
下面几种方法可以为用户生成令牌(token)
- 可以借助Django的信号(signals)实现创建用户时自动生成token(具体操作请参考信号量篇章,此处不全)
1 | from django.conf import settings |
- 如果你已经创建了一些用户,则可以运行
python manage.py shell,并运行下面代码,为所有现有用户生成令牌
1 | from django.contrib.auth.models import User |
- 还可以在
admin.py中给用户创建token
1 | from rest_framework.authtoken.admin import TokenAdmin |
- 从3.6.4起,你还可以使用如下命令为一个指定用户新建或重置token
1 | python manage.py drf_create_token <username> # 新建 |
测试
需要注意,DRF自带的API在此处可能不太好用,因为DRF 默认的登录方式是基于会话的,而不是基于 Token 的,故下面我们使用curl来测试
首先需要暴露用户获取token的url地址(API端点),在项目的urls.py中加入
1 | from rest_framework.authtoken import views |
这样每当用户使用form表单或JSON将有效的username和password字段POST提交到以上视图时,obtain_auth_token视图将响应
1 | curl -X POST -d "username=yyb&password=123" http://127.0.0.1:8000/api-token-auth/ |
客户端拿到token后可以将其存储到本地cookie或localstorage里,下次发送请求时把token包含在AuthorizationHTTP头即可,可以通过curl工具来进行简单测试
1 | curl -X GET http://127.0.0.1:8000/v1/articles/ -H 'Authorization: Token 257e09eda99e3bb9a1468aeffbeb2abcf6509f55' |
这里先关闭articles视图中的未登陆可读权限可能更明显一些
自定义Token返回信息
默认的obtain_auth_token视图返回的json响应数据是非常简单的,只有token一项。如果你希望返回更多信息,比如用户id或email,就就要通过继承ObtainAuthToken类量身定制这个视图,可在views.py中增加
1 | from rest_framework.authtoken.views import ObtainAuthToken |
然后在urls.py中更改:
1 | from blog.views import CustomAuthToken |
最后一步,DRF的TokenAuthentication类会从请求头中获取Token,验证其有效性。如果token有效,返回request.user。
JWT认证
JSON Web Token(JWT)是一种更新的使用token进行身份认证的标准。与DRF内置的TokenAuthentication方案不同,JWT身份验证不需要使用数据库来验证令牌, 而且可以轻松设置token失效期或刷新token, 是API开发中当前最流行的跨域认证解决方案
这部分将详细介绍JWT认证的工作原理以及如何通过djangorestframework-simplejwt 这个第三方包轻松实现JWT认证(相应的第三方包还有很多,我在python课程大作业开发中使用的就是jwt这一第三方包)
Json Web Token介绍
JSON Web Token(JWT)是一种开放标准,它定义了一种紧凑且自包含的方式,用于各方之间安全地将信息以JSON对象传输。由于此信息是经过数字签名的,因此可以被验证和信任。JWT用于为应用程序创建访问token,通常适用于API身份验证和服务器到服务器的授权。那么如何理解紧凑和自包含这两个词的含义呢?
- 紧凑:就是说这个数据量比较少,可以通过url参数,http请求提交的数据以及http header多种方式来传递。
- 自包含:这个字符串可以包含很多信息,比如用户id,用户名,订单号id等,如果其他人拿到该信息,就可以拿到关键业务信息。
那么JWT认证是如何工作的呢? 首先客户端提交用户登录信息验证身份通过后,服务器生成一个用于证明用户身份的令牌(token),也就是一个加密后的长字符串,并将其发送给客户端。在后续请求中,客户端以各种方式(比如通过url参数或者请求头)将这个令牌发送回服务器,服务器就知道请求来自哪个特定身份的用户了。
JSON Web Token由三部分组成,这些部分由点(.)分隔,分别是header(头部),payload(有效负载)和signature(签名)。
- header(头部):识别以何种算法来生成签名
- pyload(有效负载):用来存放实际需要传递的数据
- signature(签名):安全验证token有效性,防止数据被篡改
通过http传输的数据实际上是加密后的JWT,它是由两个点分割的base64-URL长字符串组成,解密后我们可以得到header, payload和signature三部分。我们可以简单的使用 https://jwt.io/ 官网来生成或解析一个JWT
DRF中使用JWT认证
安装
django-rest-framework-simplejwt库为DRF提供了JWT认证后端。它提供了一组保守的默认功能来涵盖了JWT的最常见用例,而且非常容易扩展。首先使用pip安装它
1 | pip install djangorestframework-simplejwt |
应用
我们需要告诉DRF我们使用jwt认证作为后台认证方案。修改apiproject/settings.py:
1 | REST_FRAMEWORK = { |
最后,我们需要提供用户可以获取和刷新token的urls地址,这两个urls分别对应TokenObtainPairView和TokenRefreshView两个视图,这部分涉及双token的设计方式,可观看双token博客部分
1 | from django.contrib import admin |
测试
现在我们可以开始使用curl测试,通过POST方法发送登录请求到/token/,请求数据包括username和password。如果登录成功,你将得到两个长字符串,一个是access token(访问令牌),还有一个是refresh token(刷新令牌)
1 | curl -X POST -d "username=yyb&password=123" http://127.0.0.1:8000/token/ |
假如你有一个受保护的视图,权限(permission_classes)是IsAuthenticated,只有验证用户才可访问。访问这个保护视图时你只需要在请求头的Authorization选项里输入你刚才获取的access token即可(注意默认设置要求在请求头中使用 Bearer 作为前缀来传递 Token)
1 | curl -X GET http://127.0.0.1:8000/v1/articles/ -H 'Authorization: Bearer eyJhbGci...' |
不过这个access token默认只有5分钟有效。5分钟过后,当你再次访问保护视图时,你将得到如下token已失效或过期的提示
1 | curl -X GET http://127.0.0.1:8000/v1/articles/ -H 'Authorization: Bearer eyJhbGci...' |
去获取新的access token,你需要使用之前获得的refresh token。你将这个refresh token放到请求的正文(body)里,发送POST请求到/token/refresh/即可获得刷新后的access token(访问令牌)
1 | curl -X POST http://127.0.0.1:8000/token/refresh/ -d '{"refresh": "eyJhbGciOiJI..."}' -H "Content-Type: application/json" |
Simple JWT中的access token默认有效期是5分钟,refresh token默认有效期是24小时
Simple JWT的默认设置
Simple JWT的默认设置如下所示:
1 | DEFAULTS = { |
如果要覆盖Simple JWT的默认设置,可以修改settings.py, 如下所示。下例将refresh token的有效期改为了15天。
1 | from datetime import timedelta |
自定义令牌
如果你对Simple JWT返回的access token进行解码,你会发现这个token的payload数据部分包括token类型,token失效时间,jti(一个类似随机字符串)和user_id。如果你希望在payload部分提供更多信息,比如用户的username,这时你就要自定义令牌(token)了
首先,编写你的myapp/seralizers.py,添加如下代码。该序列化器继承了TokenObtainPairSerializer类
1 | from rest_framework_simplejwt.serializers import TokenObtainPairSerializer |
其次,不使用Simple JWT提供的默认视图,使用自定义视图。修改 myapp/views.py, 添加如下代码:
1 | from rest_framework_simplejwt.views import TokenObtainPairView |
最后,修改apiproject/urls.py, 添加如下代码,将/token/指向新的自定义的视图
1 | path('token/', MyObtainTokenPairView.as_view(), name='token_obtain_pair'), |
重新发送POST请求到/token/,你将获得新的access token和refresh token,对重新获取的access token进行解码,你将看到payload部分多了username的内容
自定义认证后台
上面的演示案例是通过用户名和密码登录的,如果我们希望后台同时支持邮箱/密码,手机/密码组合登录怎么办? 这时我们还需要自定义认证后台
首先,修改users/views.py, 添加如下代码:
1 | from django.contrib.auth.backends import ModelBackend |
其次,修改settings.py, 把你自定义的验证方式添加到AUTHENTICATION_BACKENDS里去。
1 | AUTHENTICATION_BACKENDS = ( |
修改好后,发送邮箱/密码组合到/token/,将同样可以获得access token和refresh token
分页
当你的数据库数据量非常大时,如果一次将这些数据查询出来, 必然加大了服务器内存的负载,降低系统的运行速度。一种更好的方式是将数据分段展示给用户。如果用户在展示的分段数据中没有找到自己的内容,可以通过指定页码或翻页的方式查看更多数据,直到找到自己想要的内容为止
DRF提供的分页类
Django REST Framework提供了3种分页类
- PageNumberPagination:普通分页器。支持用户按?page=3&size=10这种更灵活的方式进行查询,这样用户不仅可以选择页码,还可以选择每页展示数据的数量。通常还需要设置max_page_size这个参数限制每页展示数据的最大数量,以防止用户进行恶意查询(比如size=10000), 这样一页展示1万条数据将使分页变得没有意义
- LimitOffsetPagination:偏移分页器。支持用户按?limit=20&offset=100这种方式进行查询。offset是查询数据的起始点,limit是每页展示数据的最大条数,类似于page_size。当你使用这个类时,你通常还需要设置max_limit这个参数来限制展示给用户数据的最大数量
- CursorPagination类:加密分页器。这是DRF提供的加密分页查询,仅支持用户按响应提供的上一页和下一页链接进行分页查询,每页的页码都是加密的。使用这种方式进行分页需要你的模型有”created”这个字段,否则你要手动指定ordering排序才能进行使用
PageNumberPagination类
DRF中使用默认分页类的最简单方式就是在settings.py中进行全局配置,如下所示:
1 | REST_FRAMEWORK ={ |
但是如果你希望用户按?page=3&size=10这种更灵活的方式进行查询,你就要进行个性化定制。在实际开发过程中,定制比使用默认的分页类更常见,具体做法如下:
第一步:在app目录下新建pagination.py,添加如下代码:
1 | from rest_framework.pagination import PageNumberPagination |
我们自定义了一个MyPageNumberPagination类,该类继承了PageNumberPagination类。我们通过page_size设置了每页默认展示数据的条数,通过page_size_query_param设置了每页size的参数名以及通过max_page_size设置了每个可以展示的最大数据条数。
第二步:使用自定义的分页类
在基于类的视图中,你可以使用pagination_class这个属性使用自定义的分页类,如下所示:
1 | from .pagination import MyPageNumberPagination |
当然定制分页类不限于指定page_size和max_page_size这些属性,你还可以改变响应数据的输出格式。比如我们这里希望把next和previous放在一个名为links的key里,我们可以修改MyPageNumberPagination类,重写get_paginated_response方法
1 | from rest_framework.pagination import PageNumberPagination |
注意:重写get_paginated_response方法非常有用,你还可以给分页响应数据传递额外的内容,比如code状态码等等
前面的例子中我们只在单个基于类的视图或视图集中使用到了分页类,你还可以修改settings.py全局使用你自定义的分页类,如下所示。展示效果是一样的,我们就不详细演示了。
1 | REST_FRAMEWORK = { |
LimitOffsetPagination类
使用这个分页类最简单的方式就是在settings.py中进行全局配置,如下所示:
1 | REST_FRAMEWORK = { |
你也可以自定义MyLimitOffsetPagination类,在单个视图或视图集中使用,或者全局使用
1 | from rest_framework.pagination import LimitOffsetPagination |
CursorPagination类
使用这个分页类最简单的方式同样是在settings.py中进行全局配置
1 | REST_FRAMEWORK = { |
如果出现错误,是因为使用CursorPagination类需要你的模型里有created这个字段,否则你需要手动指定ordering字段。这是因为CursorPagination类只能对排过序的查询集进行分页展示。我们的Article模型只有create_date字段,没有created这个字段,所以会报错
为了解决这个问题,我们需要自定义一个MyCursorPagination类,手动指定按create_date排序, 如下所示:
1 | from rest_framework.pagination import CursorPagination |
修改settings.py, 使用自己定义的分页类
1 | REST_FRAMEWORK = { |
结果中你将得到previous和next分页链接。页码都加密了, 链接里不再显示页码号码。默认每页展示3条记录, 如果使用?page_size=2进行查询,每页你将得到两条记录
当然由于这个ordering字段与模型相关,我们并不推荐全局使用自定义的CursorPagination类,更好的方式是在视图的pagination_class属性指定
函数类视图中使用分页类
注意pagination_class属性仅支持在genericsAPIView和视图集viewset中配置使用。如果你使用函数或简单的APIView开发API视图,那么你需要对你的数据进行手动分页,一个具体使用例子如下所示:
1 | from rest_framework.pagination import PageNumberPagination |
过滤与排序
本节将演示三种过滤方法, 你可以根据实际项目开发需求去使用
重写get_queryset方法
此方法不依赖于任何第三方包, 只适合于需要过滤的字段比较少的模型。比如这里我们希望对文章title进行过滤,我们只需要修改ArticleList视图函数类即可
1 | from rest_framework import generics |
修改好视图类后,发送GET请求到/v1/articles?page=1&q=django, 你将得到所有标题含有django关键词的文章列表
注意:DRF中你通过request.query_params获取GET请求发过来的参数,而不是request.GET。如果你希望获取从URL里传递的参数,你可以使用self.kwargs['param1']。二者的区别在于query_params用于URL中的查询字符串参数,即问号后的内容,而self.kwargs['param1']用于获取URL路径中通过正则表达式捕获的参数
假如你的URL配置如下所示:
1 | re_path('^articles/(?P<username>.+)/$', AricleList.as_view()), |
在视图中你可以通过self.kwargs['username']获取URL传递过来的用户名。
1 | class ArticleList(generics.ListAPIView): |
使用django-filter
当一个模型需要过滤的字段很多且不确定时(比如文章状态、正文等等), 重写get_queryset方法将变得非常麻烦,更好的方式是借助django-filter这个第三方库实现过滤
django-filter库包含一个DjangoFilterBackend类,该类支持REST框架的高度可定制的字段过滤。这是最推荐的过滤方法, 因为它自定义需要过滤的字段非常方便, 还可以对每个字段指定过滤方法(比如模糊查询和精确查询)
安装django-filter
1 | pip install django-filter |
把django_filters添加到INSTALLED_APPS中去。
1 | INSTALLED_APPS = [ |
接下来你还需要把DjangoFilterBackend设为过滤后台。你可以在settings.py中进行全局配置。
1 | REST_FRAMEWORK = { |
还可以在单个视图中使用它,在类视图中使用django-filter时,你可以直接通过filterset_fields设置希望过滤的字段,如下所示:
1 | from django_filters import rest_framework |
如果你希望进行更多定制化的行为,你需要自定义FilterSet类,然后指定filter_class
自定义FilterSet类
新建blog/filters.py, 添加如下代码:
1 | import django_filters |
接下来通过filter_class使用它
1 | from django_filters import rest_framework |
发送GET请求到/v1/articles?page=2&q=django&status=p, 你将得到只包含发表了的文章
你还可以看到REST框架API测试部分提供了一个新的Filters下拉菜单按钮,可以帮助您对结果进行过滤
方法三: 使用SearchFilter类
其实DRF自带了具有过滤功能的SearchFilter类,其使用场景与Django-filter的单字段过滤略有不同,更侧重于使用一个关键词对模型的某个字段或多个字段同时进行搜索
使用这个类,你还需要指定search_fields, 具体使用方式如下:
1 | from rest_framework import filters |
可发送GET请求到/v1/articles?page=1&search=django测试
注意:这里进行搜索查询的默认参数名为?search=xxx
SearchFilter类非常有用,因为它不仅支持对模型的多个字段进行查询,还支持ForeinKey和ManyToMany字段的关联查询。按如下修改search_fields, 就可以同时搜索标题或用户名含有某个关键词的文章资源列表。修改好后,作者用户名里如果有django,该篇文章也会包含在搜索结果了
1 | search_fields = ('title', 'author__username') |
默认情况下,SearchFilter类搜索将使用不区分大小写的部分匹配(icontains)。你可以在search_fields中添加各种字符来指定匹配方法。
- ’^’开始-搜索
- ’=’完全匹配
- ’@’全文搜索
- ’$’正则表达式搜索
例如:search_fields = (‘=title’, )精确匹配title
自定义SearchFilter类
默认SearchFilter类仅支持?search=xxx这个传递参数,你可以通过设置SEARCH_PARAM覆盖。另外你还可以重写get_search_fileds方法改变它的行为。下例中,当你按照/?search=keyword&title_only=True提交请求时,它将只针对title进行查询。
1 | from rest_framework import filters |
排序OrderingFilter类
使用OrderingFilter类首先要把它加入到filter_backends, 然后指定排序字段即可,如下所示:
1 | from rest_framework import filters |
发送请求时只需要在参数上加上?ordering=create_date或者?ordering=-create_date即可实现对结果按文章创建时间正序和逆序进行排序
注意:实际开发应用中OrderingFilter类,SearchFilter类和DjangoFilterBackend经常一起联用作为DRF的filter_backends,没有相互冲突
限流
限流概念
限流(Throttle)就是限制客户端对API 的调用频率,是API开发者必须要考虑的因素。比如个别客户端(比如爬虫程序)短时间发起大量请求,超过了服务器能够处理的能力,将会影响其它用户的正常使用。又或者某个接口占用数据库资源比较多,如果同一时间该接口被大量调用,服务器可能会陷入僵死状态。为了保证API服务的稳定性,并防止接口受到恶意用户的攻击,我们必须要对我们的API服务进行限流
DRF中限制对API的调用频率非常简便,它为我们主要提供了3个可插拔使用的限流类:
AnonRateThrottle用于限制未认证用户的请求频率,主要根据用户的 IP地址来确定用户身份。UserRateThrottle用于限定认证用户的请求频率,可对不同类型的用户实施不同的限流政策。ScopeRateThrottle可用于限制对 API 特定部分的访问。只有当正在访问的视图包含throttle_scope属性时才会应用此限制。这个与UserRateThrottle类的区别在于一个针对用户限流,一个针对API接口限流。
DRF限制频率的指定格式为 “最大访问次数/时间间隔”,例如设置为 5/min,则只允许一分钟内最多调用接口 5 次。其它常用格式包括”10/s”, “100/d”等。超过限定次数的调用将抛出 exceptions.Throttled异常,客户端收到 429 状态码(too many requests)的响应。
全局使用限流类
现在我们尝试对/v1/articles/这个接口增加限流,匿名用户请求频率限制在2/min,而认证用户请求频率限制在10/min
最简单的使用DRF自带限流类的方法,就是在settings.py中进行全局配置,一是要设置需要使用的限流类,二是要设置限流范围(scope)及其限流频率。AnonRateThrottle和UserRateThrottle默认的scope分别为”anon”和”user”。该配置会对所有API接口生效
1 | REST_FRAMEWORK = { |
视图类或视图集中使用限流类
DRF中还可以在单个视图或单个视图集中进行限流配置,单个视图中的配置会覆盖全局设置。现在我们希望保留settings.py的限流全局配置,并专门为文章资源列表/v1/articles定制一个限流类,新的访问频率限制为匿名用户为5/min,认证用户为30/min,该配置仅对文章资源列表这个接口生效
我们首先在app文件夹blog目录下新建throttles.py, 添加如下代码:
1 | from rest_framework.throttling import AnonRateThrottle, UserRateThrottle |
我们通过继承自定义了ArticleListAnonRateThrottle, ArticleListUserRateThrottle两个类,并通过THROTTLE_RATES属性设置了新的访问频率限制。现在我们可以将它们应用到views.py中对应文章资源列表的API视图类
1 | from .throttles import ArticleListAnonRateThrottle, ArticleListUserRateThrottle |
有时对一个认证用户进行限流不仅要限制每分钟的请求次数,还需要限制每小时的请求次数,我们可以自定义两个UserRateThrottle子类,并设置不同的scope,如下所示:
1 | from rest_framework.throttling import AnonRateThrottle, UserRateThrottle |
然后修改我们的视图类,使用新的限流类:
1 | throttle_classes = [HourUserRateThrottle, MinuteUserRateThrottle] |
现在我们只指定了限流类,还未设置限流频率,可以去settings.py中设置,也可以在自定义限流类中通过THROTTLE_RATES属性指定。
1 | REST_FRAMEWORK = { |
ScopeRateThrottle类
AnonRateThrottle和UserRateThrottle类都是针对单个用户请求进行限流的,而ScopeRateThrottle类是针对不同API接口资源进行限流的,限制的是所有用户对接口的访问总数之和。使用时直接在视图类里通过throttle_scope 属性指定限流范围(scope), 然后在settings.py对不同scope设置限流频率。例子如下所示:
1 | class ArticleListView(APIView): |
针对不同api接口设置不同限流频率。如下配置代表文章资源列表一天限1000次请求(所有用户访问数量之和),文章详情接口限1小时100次。
1 | REST_FRAMEWORK = { |
自定义限流类
有时你还需要自定义限流类。这时你需要继承BaseThrottle类、SimpleRateThrottle或者UserRateThrottle类,然后重写allow_request(self, request, view)或者get_rate(self, request=none)方法。DRF给的示例方法如下所示,该限流类10个请求中只允许一个通过。
1 | import random |
- 标题: Django之DRF
- 作者: rainbowYao
- 创建于 : 2024-08-21 23:56:36
- 更新于 : 2024-09-18 09:21:54
- 链接: https://redefine.ohevan.com/2024/08/21/Django之DRF/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


